Meet your Instructor - Constanze - Staff Engineer at the VSC-Research Center

Last Updated: 2023-12-24
Why teach LVA HandsOn Cloud Native 194131?
The "Austrian DataLAB and Services" and the associated "AustrianOpenCloudCommunity" demonstrates how digital technologies can be used in teaching and research. So, in 2022, we asked the ministry to approve a prototypical lecture to also teach the cloud technologies on top of our newly created cloud stacks. Summer 2024 is the second round of lectures, which will partially be recorded and converted into self-service labs.
The infrastructure belongs exclusively to TUWien and the VSC, however, any student from any university is welcome to co-enroll.
The lectures follow the Open Source philosophy and aim to convey the value of open source mentality, mindset, culture and its value (cf https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4693148 )
For whom is this LVA "Hands On Cloud Native"?
For students who are reasonably skilled at overall software engineering and who would like to leverage cloud computing and cloud capabilities to widen the impact of their engineering creativity.
Specifically, students who are playing with the idea of founding a tech startup, this class will give them a solid overview over the challenges of operations, security, product placement and team work. Cloud native is one option to realize a product idea without too much up-front investment, however, it is not without its own challenges. And to this end, this class is designed to give a practical and experience driven overview, covering the most crucial aspect of bringing a software product to market.
The topics covered are:
- Shared ownership
- Time management and "buy versus build"
- Security concerns, Identity Standards and Zero Trust
- Incremental design and development
- Rapid prototyping, contracts (APIs) abstractions and incremental decision making
- User focus and the importance of product experience
- Distributed systems and their pitfalls
- Containers, Artefacts and Registries
- How did Kubernetes become the de-facto standard and what are the most important design patterns
- What else is Cloud-Native (beyond Kubernetes)? What mental models do we need to navigate the Cloud Native landscape?
All classes contain Architecture, Security, Development, Operations, Management and Psychology topics, the students will be treated as mature adults and expected to use their own best judgment in how to solve problems. Exams are open-book. Constructive behaviour and active problem solving is encouraged and participants can actively contribute to the content of these labs.
licensed under Creative Commons Attribution-NonCommercial 2.5 license, retrieved from xkcd
What to expect in each week
Each week of the course is dedicated to one topic and the pedagogical approach is based on "agency" and "creativity", teamwork is explicitly required as it is close to real life.
You will explore fundamental concepts (from scratch) and real-life problems
You will be given homework to adequately prepare you for the hands-on class.
You will be working on live systems and you will receive a cloud account. You are responsible for treating your accounts with adequate due diligence and be aware that we live in a time and age, where everything that is on the internet, is fair game (Freiwild).
What you'll build during these lectures
By the end of the semester, your startup (team) will have a running service that includes the following deliverables:
- ✅ a value proposition
- ✅ a target audience
- ✅ a 60 seconds TL;DR what your startup does and why anyone should care (in the main Readme)
- ✅ one released artifact
- ✅ one Dockerfile (or equivalent recipe)
- ✅ one meaningful (unit or integration) CI test
- ✅ no critical vulnerabilities
- ✅ one repo with your team
- ✅ a license
- ✅ at least three decision records (e.g. ADRs)
- ✅ a versioning scheme (how do you increment versions)
- ✅ a CD pipeline that can be triggered manually
- ✅ a package (e.g. a Helm Chart)
- ✅ a Readme that explains how to use it
And:
- ✅ Discuss your Lessons Learnt (either by choosing a suitable perspective of the presentation or in a separate section of the presentation)
What you'll need
- A Microsoft Authenticator app on a reasonable smartphone
- Git installed on your laptop (Linux or Mac)
- A browser (this lab was only tested on Chrome)
- In classroom: bring an extension cord and pen/paper
- A laptop that runs Linux or MacOS
- An account on our SLACK (ask Constanze)
Desired Learning Outcome
- Understand how the Service orientation (xaaS) shifts ownership, risks, time and other quantities
- Learn how to bootstrap a cloud account and the cadence of life-cycle coupling
- Learn how gitOps with Terraform is stateful and how that is different from "normal" code
What you'll build
Over the semester, you will form teams that will build a very simple product on your "own" cloud account.
In this first week, we will focus on "Cloud, Automation and Infrastructure as Code":
- We will bootstrap an empty cloud account
- We will use two of the most famous Infrastructure Automation tools: Terraform and Ansible to contrast declarative, idempotent and imperative infrastructure configuration
- We will provision a Vault to manage your secrets
- We will provision a Storageaccount with version control and encryption
- Team-Homework: You will provision an identity-aware bastion host in a private network using 100% automation (you will use the cloud account we setup today).
Homework (Flipped Classroom)
Prepare
- Download a copy of Project Value Proposition
- Create a clear mental picture of why you want your service (for your startup) to exist and fill out the Project Value Proposition File (if you already have a team, you can do it as a team)
- Make sure you have git setup on your laptop
- if for any reason, you haven't setup the Authenticator app for MFA, please do it now
- test if the TuWien VPN works on your laptop
PreRead
- "Terraform up and running" (3rd edition) -> download it from the TU library onto your app. You might have to SSO-login twice
Chapter 1 : please read up to this point https://learning.oreilly.com/library/view/terraform-up-and/9781098116736/ch01.html#:-:text=It's a bit like telling a,or making a good decision - Self identify if you need to review some git basics
Evolutionary architecture is the art of constraining the parameter space such that entropy evolves into consistent patterns
(Credit to Forrest Brazeal)
Building infrastructure in a world that changes
Today's class is about starting your cloud journey in such a way that you don't have technical debt from Day 1. The setup is necessarily tedious, but will stay with you for the duration of the semester, thus your diligence will pay off.
We must realise that in the cloud "everything moves" . So, if we aim to build a foundation, it must be a foundation that is rock solid while being able to handle constant change.
Mental models
From Day 1, you are encouraged to create a mental practise of internally visualizing all components that you have in play and their mutual interactions and interdependencies. You may use any productivity tools that you find helpful.
The minimal set of ingredients for working with the cloud are:
- An account with a global billing setup
- An IDP (Identity Provider) so users can login
- Roles and a method to bind a user to a role
- A logical segment in your account
- A network
- A root key (this doesnt necessarily equate to a password)
- A vault for the root key
- A "buildagent" or "runner" : something that executes the automation
Exercise
Take your paper and your pen
Sketch how you could setup the "bootstrap segment" of your cloud account.
Security Considerations
The cloud bootstrap is where we handle the most powerful credentials , however, unfortunately, here is where most companies make mistakes because it can be a bit of a chicken/egg problem or because an account is setup quickly, and never cleaned up.
From a threat-modelling perspective, we will defend against our worst opponent: ourselves as cloud admins: How can I protect my own accounts, if I am *compromised, *tired, *sick (Covid-fog, real story) or otherwise acting against my own best interests.
It is thus absolute paramount that we securely bootstrap our automation, with so-called break-glass and remove ourselves (as admins) from direct contact with our crown-jewels:
- The root "key" is never touched by a human, it lies in a vault
- This vault has maximal network/identity and detection capabilities switched ON
- This is where we spend money on premium tier security monitoring, audit tracing etc
- The vault can only be accessed from a known location with a known identity that uses strong cryptography to authenticate itself. This identity is not the cloud-admin, s/he needs at least one break-glass action to get there.
- If the root "key" is in fact a machine- identity, then access to the identity (usually audit logs in the corresponding IDP) is strictly monitored.
- All bootstrap components live in their own private network segment AND own logical namespace
- The root key is primarily used to generate secondary, less powerful keys and bootstrap the "normal" namespaces/networks etc
- The bootstrap segment has its very own statefile (more about statefiles later), it is ENCRYPTED and visibility is set to PRIVATE
Shared ownership
The fundamental design principle behind modern cloud efficiency is abstraction, ie to each their own: each part of the stack is owned , maintained and developed by a dedicated entity. In case of the large hyperscalers, this means that and a developer is treated as an end user for eg Microsoft, whereas for the company that employs the developer, Microsoft may only be one of many service providers and their customers may never know that Microsoft is involved.
This leads to a highly distributed net of shared ownerships. There is no one way to define any one relationship, as consumers we must read and stay up to date with terms and conditions and SLO (service level objectives). This is relevant especially for liabilities but even for individuals just playing around: violating TnCs accidentally can e.g. lead to you being silently shunned.
It depends...
One thing is for sure though: you need to be very aware of what pieces of your platform or service you own and control, and which you don't. And what you will do if a service fails.
See for our Microsoft example an illustration ( make sure to check if it's up to date if you want to use it for decisions making).

BTW: say No to ClickOps
It can be tempting to manually generate things by clicking on buttons in UIs, but it always backfires. This is why we have all this lab in code. One of your key learnings this week will be to generate a mental image on "who is doing what on behalf of whom" and it is important to draw this mental image and compare it with the code and the currently existing state. Until they all match.
Automation
"Cloud" in the very beginning was just "Infrastructure as a Service" . Nowadays it is so much more and - if correctly leveraged - cloud can be extremely powerful. One of the biggest reasons is the open source nature of "How to do something" and being able to replicate other peoples projects, combine them, modify them and build on top "of the shoulders of giants".
This means that *everything* is written "as Code" and lies in git and gets applied via some form of automation.
Do yourself a service, and keep your infrastructure, your configuration, your init files, your patches, your policies, your users and your role-bindings and and and .... in git .
The CNCF landscape : open source projects in the Automation Space
Please read: CNCF Landscape - Automation Tile

For the HandsOn portion, we will use openTofu("Terraform") and Ansible, today on Azure. We will meet Openstack later in class. Note that this landscape doesnt include all tools and projects, some have been declared "winners" and are de-facto standards whereas others may not survive much longer or have been de-facto deprecated. One notable absence in the landscape is crossplane.io , which may be included in future versions of this class.
Key takeaway: Declarative vs Imperative
In order to fulfill the promise of build-once run anywhere, we need to be foolproof. And commands over network to some API: can fail. Thus, many designs are eventually consistent and failure tolerant from first principle.
Most importantly, when we design our instructure as code, the state in git must match the state on the cloud: thus , running code multiple times must yield the same result: This is called idempotency and we will meet this principle again in message queues and in k8s.
When choosing how to create and manage large infrastructures, we thus "declare" our desired target state which is committed to version control, this file is translated via automation into API calls that make sure that the cloud state equals the text in the file. We as humans have no control over the order in which the state is eventually achieved.
Sometimes, we need configuration (deamons, mounts etc) that just don't work this way, for them we use (also idempotent please) imperative methods.
TLDR
- Clone the repo and branch of features/example
- Login to portal.azure.com , compare the *.tf files with what you see
- Setup manually a backend for Terraform
- Appreciate the multitude of roles in Azure RBAC/IAM
- You need to impersonate Terraform in the automation and bind roles correctly
- Forward the secrets to a CI/CD tool via a
Service Connection - Set the Variables in
Library Contexts - Run Terraform from the right branch
- Run Terraform in the right stage
- Deal with the Approval nightmare
- Once it works, draw out your own virtual infrastructure design for
your current stage, be intentional
1.Git Clone and branch
It will be very important to run from the correct branch and the correct stage of a pipeline.
git clone git@ssh.dev.azure.com:v3/AOCC-Lectures/HandsOnCloudNative/HandsOnCloudNative cd HandsOnCloudNative git checkout features/example git checkout -b features/<myname>
Some branches from last year are still there, you can use them for reference. You need to make sure that your ssh key is known to AzureDevOps
2. Azure portal (or GCP cloud console)
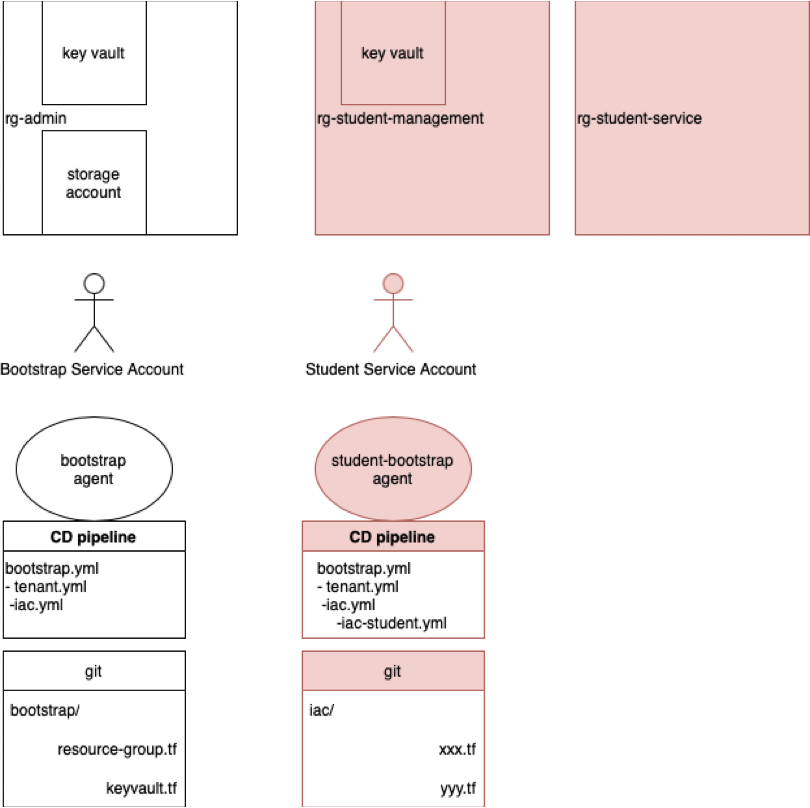
Now, we will face the first problem in multi-tenant environments: finding the right tenant (or directory) . Whether in the IDPs, kubernetes clusters on the cloud portals, everything looks the same in each tenant, but it is crucial to be in the right one, this applies to CLI as well as UI.
- Check what user you logged in as
- Check your current context
So much stuff
Navigate around in the Azure Portal. Your most useful feature is "All Resources", unfortunately neither AWS nor GCP have this feature, it is great to get an overview.
You should see two resource groups, in one there is a key vault. Check it out, click around, explore your options and compare with the suggestions listed above in the Security Considerations.. In the vault, there are the credentials to your logical section of this cloud account. Treat this as if it were your root-key. You do *not need to ever take them out of the vault as you'll see below.
3. Terraform Backend : ClickOps zum Abgewöhnen
Now, we need to solve the chicken and egg problem of "creating state" , i.e. we need a place to safely store a statefile that the automation agent can access, but we can't yet run the agent to create that place. Your statefile(s) are absolutely crucial, they contain sensitive information and hold the current truth. But, they are just json files, so we use some cloud-native features, to make sure, we don't accidentally mess them up:
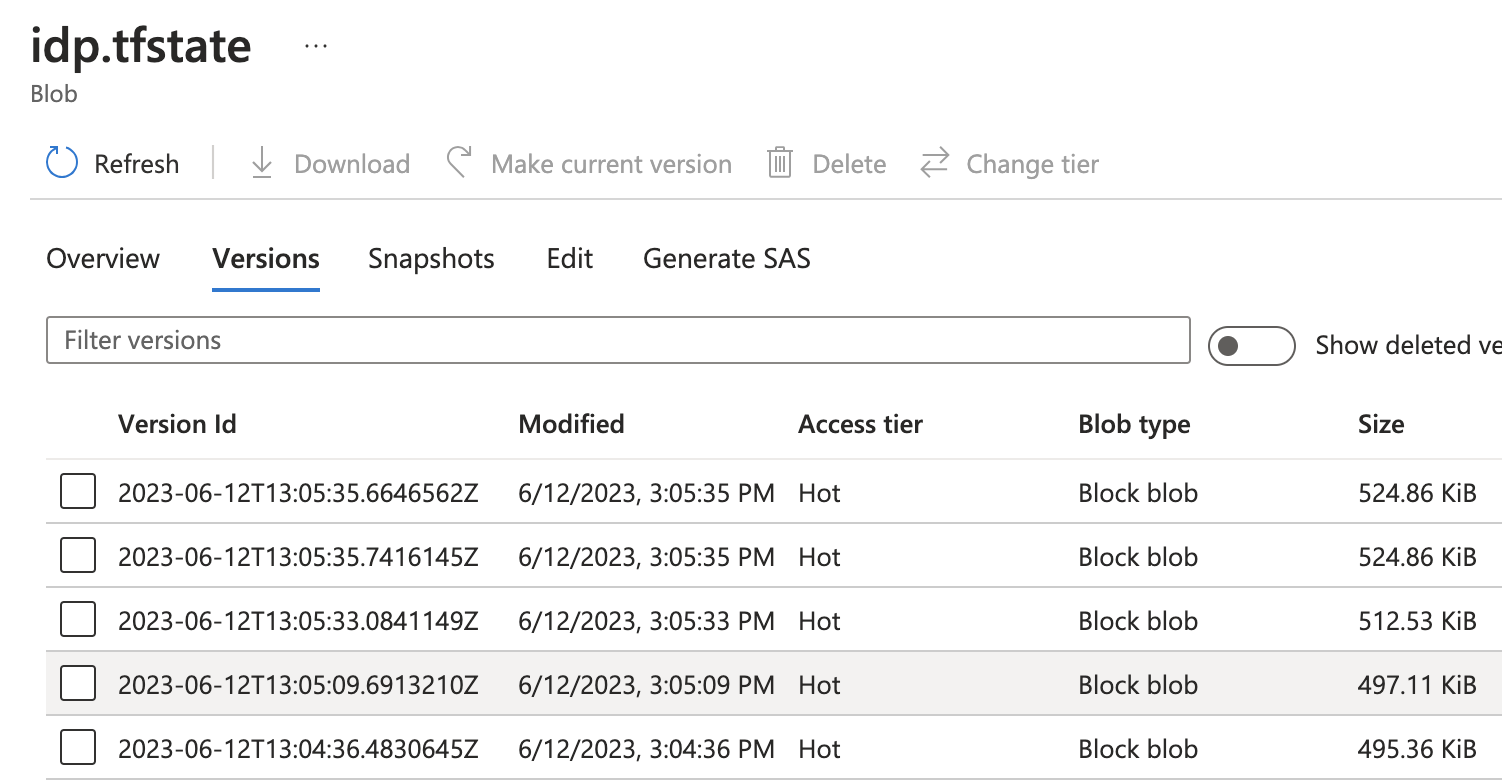
iac.tfstate
<!-- CODELAB: an empty statefile -->
{
"version": 4,
"terraform_version": "1.6.6",
"serial": 23,
"lineage": "8dfadfe-1853-19d1-6c6d-7bfde3191b5e",
"outputs": {},
"resources": [],
"check_results": null
}
So, now, you need to manually create such a Azure Storage account and inside it a (Blob Storage) Container with the right properties, using the UI. This is an anti-pattern exercise, so you will please not do manual UI ever again 😀
Your settings are:
Issue | Setting | Why | Comment |
Location | West Europe | we want GDPR to apply | typically put in same location as your assets, since this is mostly a legal question |
Encryption** | Yes (provided by Microsoft) | You need to protect this file! | it is one of the most sensitive files you have, in terms of powerful credentials, especially if its a bootstrap statefile |
Immutability | Yes (in Production) | Audit and traceability | also debugging and protection against accidental overrides |
Replication | LRS (for this demo), GRS | In Prod, you need this redundant, in case Azure has an outage | Depends on your reliability requirement and cost-willingness |
**Encryption: You could bring your own key, that is quite feasible. Please do not use a HSM (Hardware Security Module) , they are very expensive and have purge-protection. Please do not switch on Microsoft Defender (we will discuss what it does in class).
NetworkAccess in Storage Account
In order for your build agent to reach the statefile stored in the storage account, you need to allowlist the IP ranges of the Azure hosted build agents, on which your terraform will be running.
Microsoft publishes these ranges regularly, e.g. here
https://www.microsoft.com/en-us/download/details.aspx?id=56519
Container in Storage Account
This is Azure terminology and means that we partition our blob storage. This is useful because each Container can have different properties and access rights.
Meet the client side: the pipeline.yml that executes the automation
Here comes the next piece, a pipeline: the client code that is accessing the storage backend. This pipeline agent executes the terraform command and directs it to the correct storage account, wherein terraform will then store its state and compare IS versus SHOULD. It is your task to make the values of your names match on client (pipeline.yml in git) and backend ( Resource Group Name, Storage Account and Blob Storage Container )
Please update your paper drawing at this point to reflect the "agent" and the "backend".
You will notice a value called key, this is the name of the statefile inside the Container. We will demonstrate later in this lab, what happens when you mismatch it (Hint: desaster).
templates/iac-student.yaml
export TF_CLI_ARGS_init=" -backend-config=\"resource_group_name=$(AZURERM_resource_group_name)\" -backend-config=\"key=$(key).tfstate\" -backend-config=\"storage_account_name=$(AZURERM_storage_account_name)\" -backend-config=\"container_name=tfiac\" -backend-config=\"subscription_id=$(AZURERM_subscription_id)\" -backend-config=\"tenant_id=$(AZURERM_tenant_id)\" "
4) Appreciate the multitude of roles in Azure RBAC/IAM
I'm sure you have heard of least privilege. Click on the AccessControl (IAM) button and go to Roles to get an idea of what options you have. After all, we need to first allow the automation to do anything to your Storage Account, key is to find the role that has just enough rights.
You should also check the Networking tab of the Storage Account: In a production setup, you need additional controls, so you would run bootstrap from a single controlled machine with a well known IP, and only this IP can access the storage account.
We are skipping the network security portion in the exercise, since previous experience shows that this will cause the debugging to be endless.
5) Let the automation impersonate a service account to execute terraform
Your automation as declared inside a pipeline.yml file, will be executed on a temporary runtime referred to as agent. This agent needs to non-interactively obtain an access token that is correctly scoped for its automation task (in this case terraform).
Thus, you need to give the service-principal that terraform will assume, the correct roles to do its job, whilst observing least privilege :
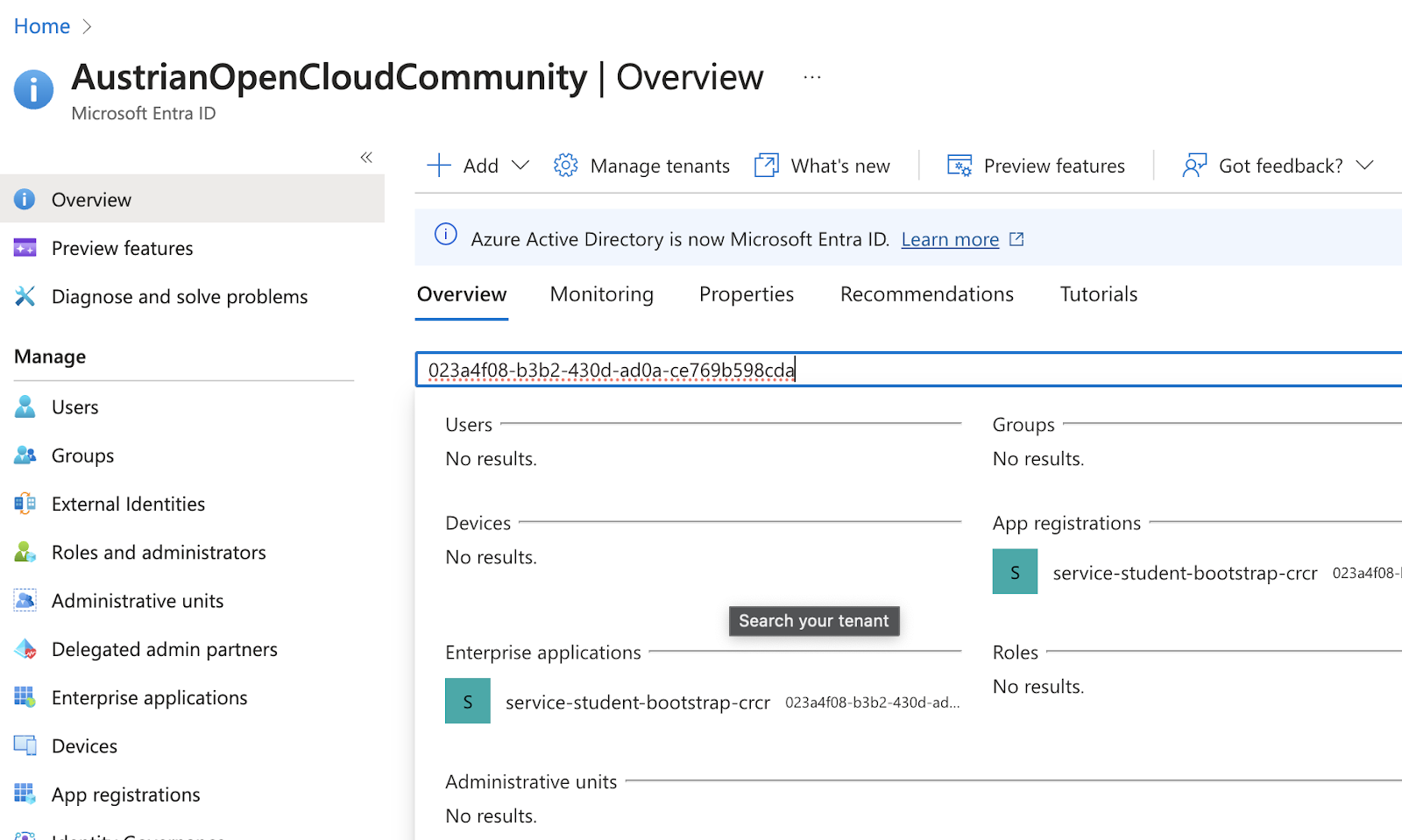 Via the UI, assign the role of
Via the UI, assign the role of Storage Blob Data Contributor to service-student-bootstrap- on the storage account and container level. Else you will get 403 or Role Mismatch.
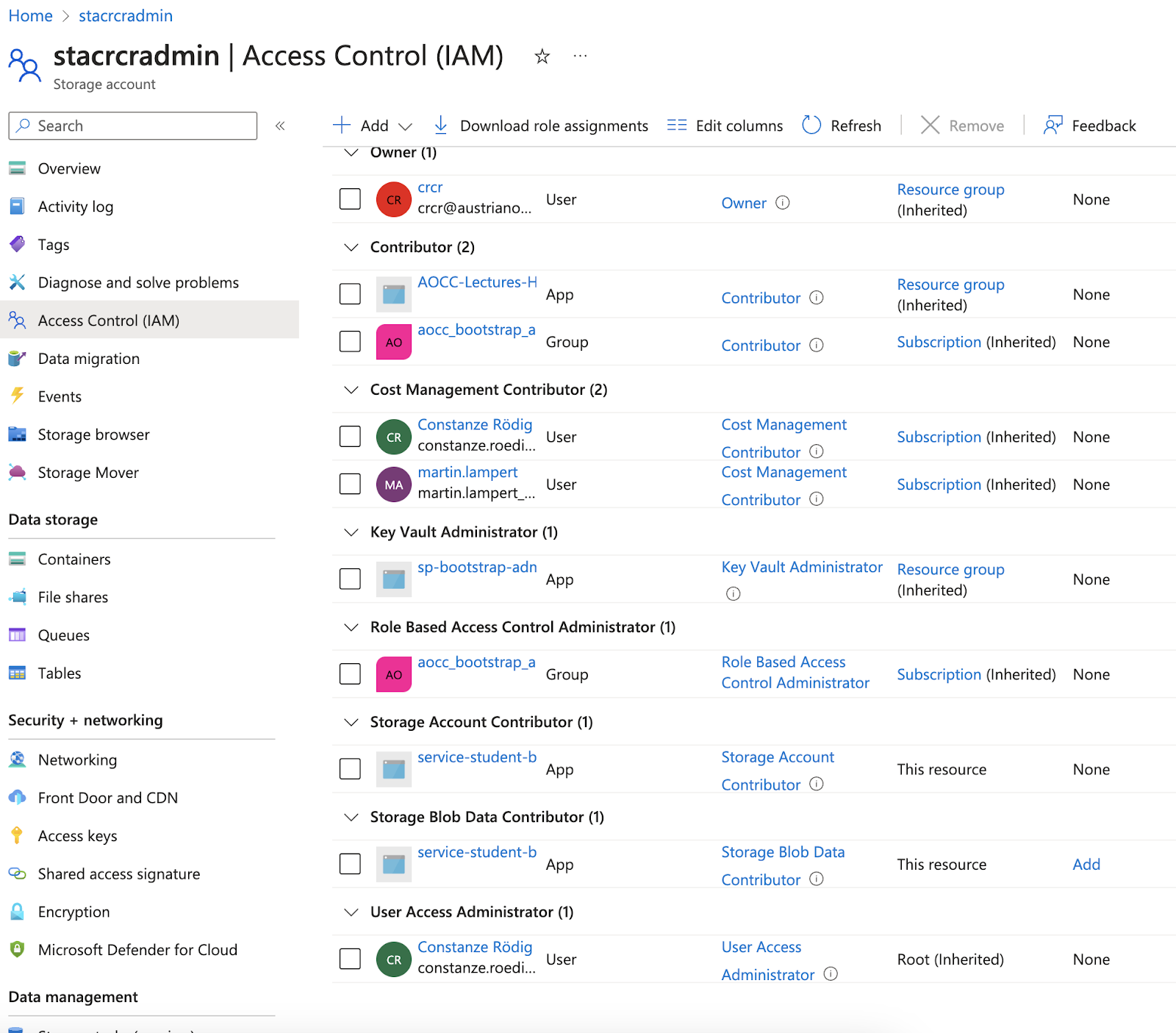
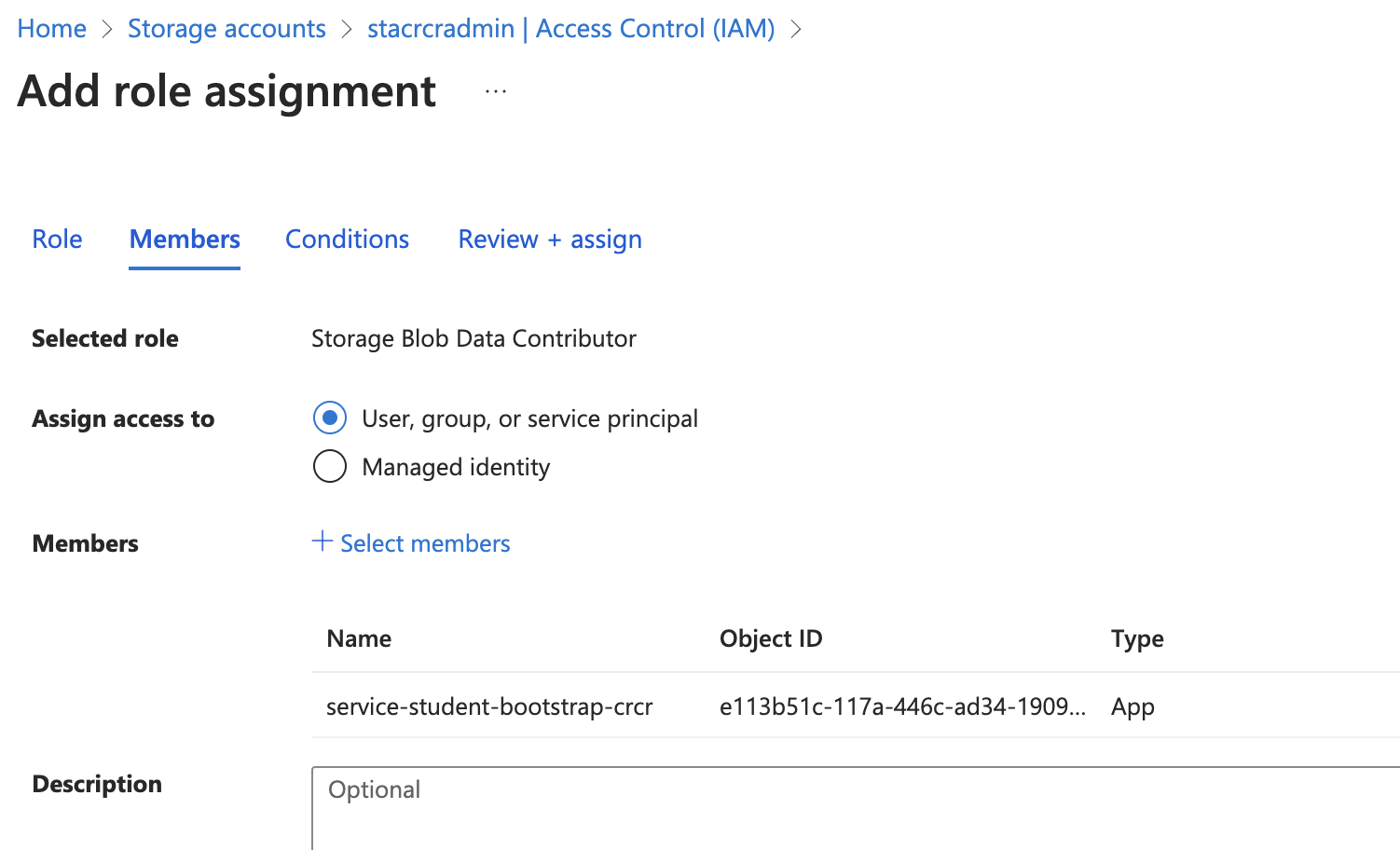
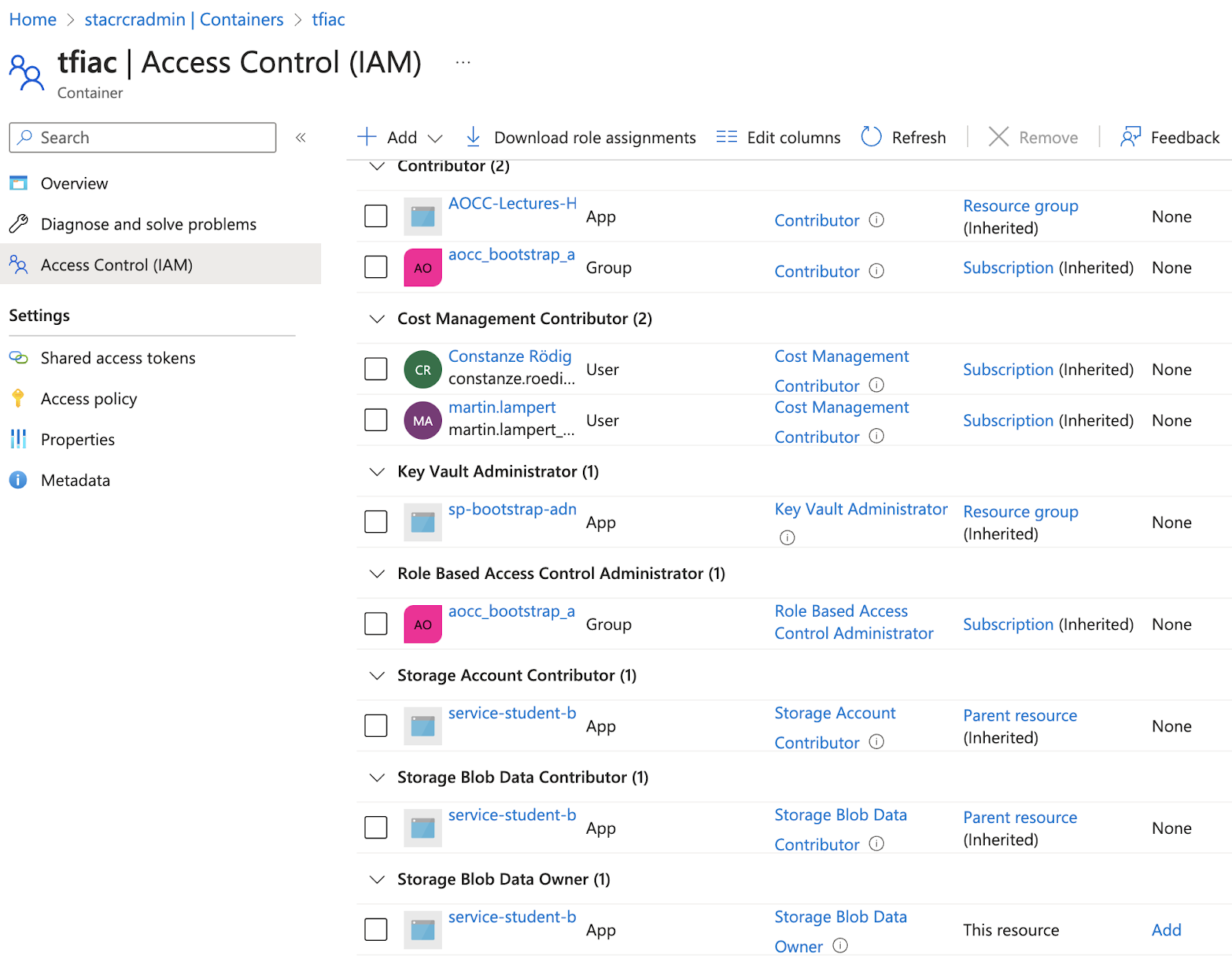
Add this to your drawing, bonus exercise: how would you restrict the network access?
6) Forward the secrets to the CI/CD tool via a Service Connection
In this Lab, we use Azure, so we pair it with the cloud-native CI/CD tool that seamlessly integrates with Azure and allows us to connect to the Key Vault without ever touching any values inside the vaults.
Go to Pipelines-> Libraries, create a Library iac-admin-student- and link your service-principal into it.
In order to authorize it, you need to correctly scope the service connection by pressing the blue button down arrow and filling it out like so
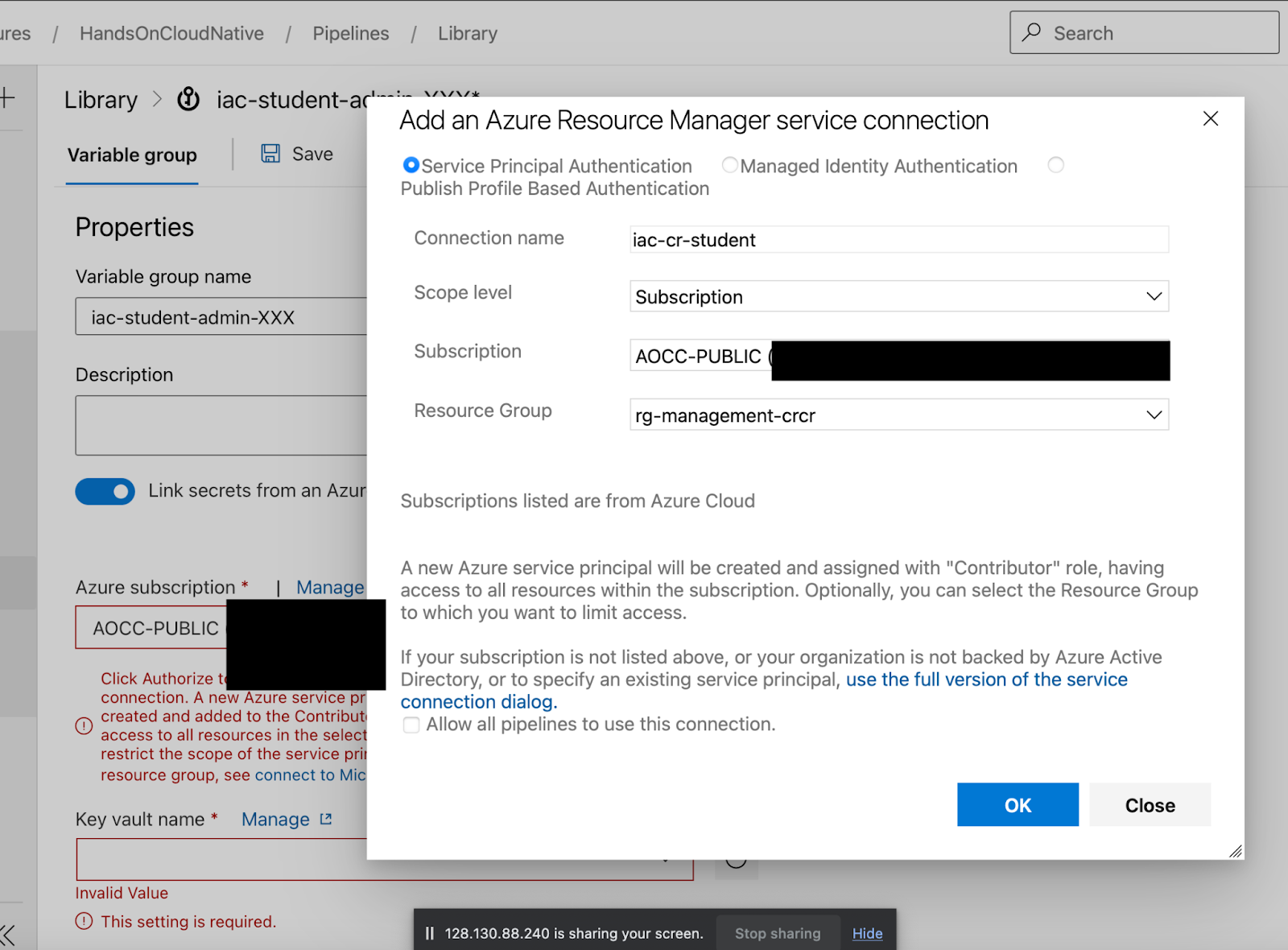
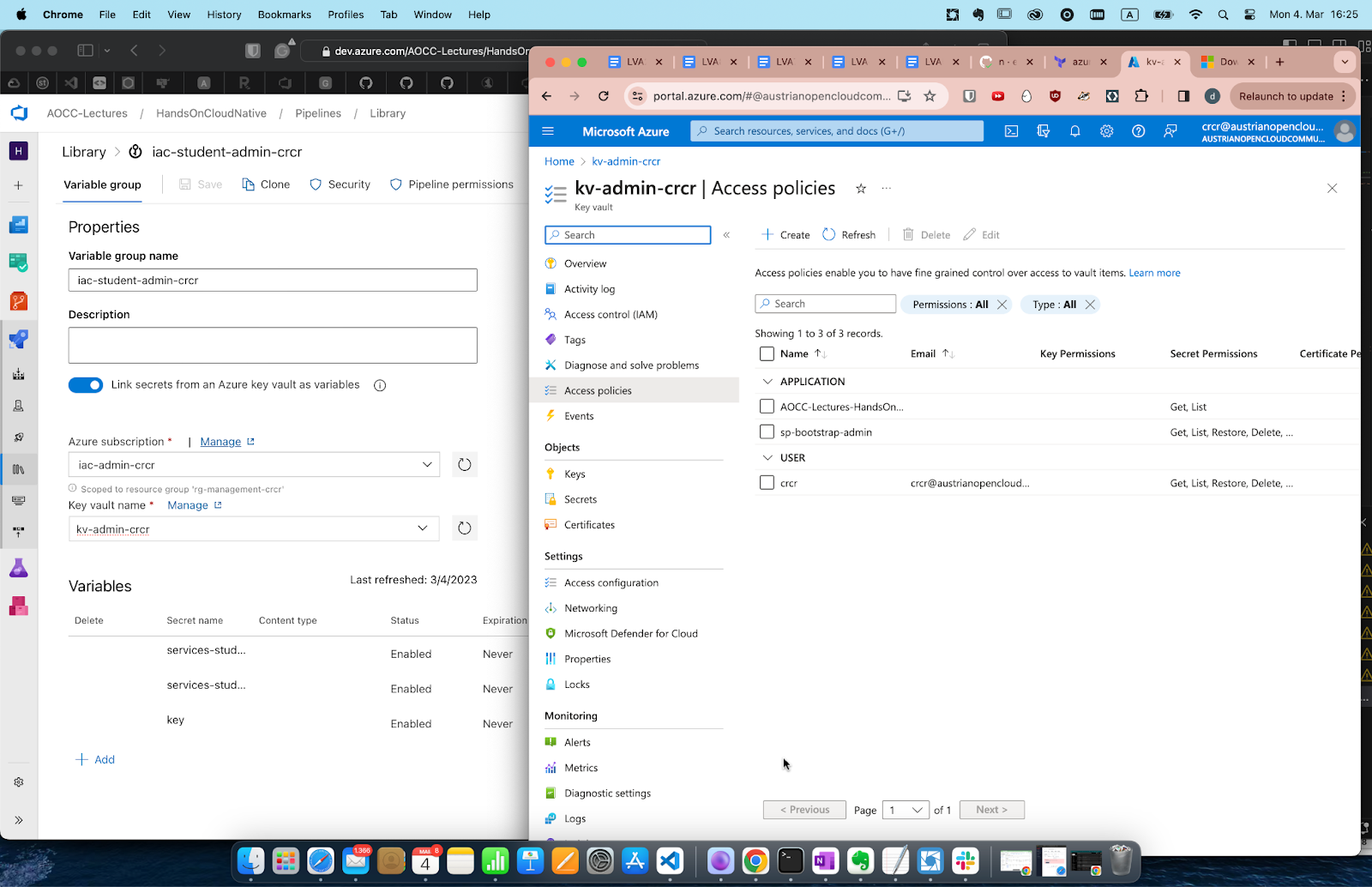
The secret "key" is what TF is looking for a "name" inside the storage container (called tfiac see next screenshot).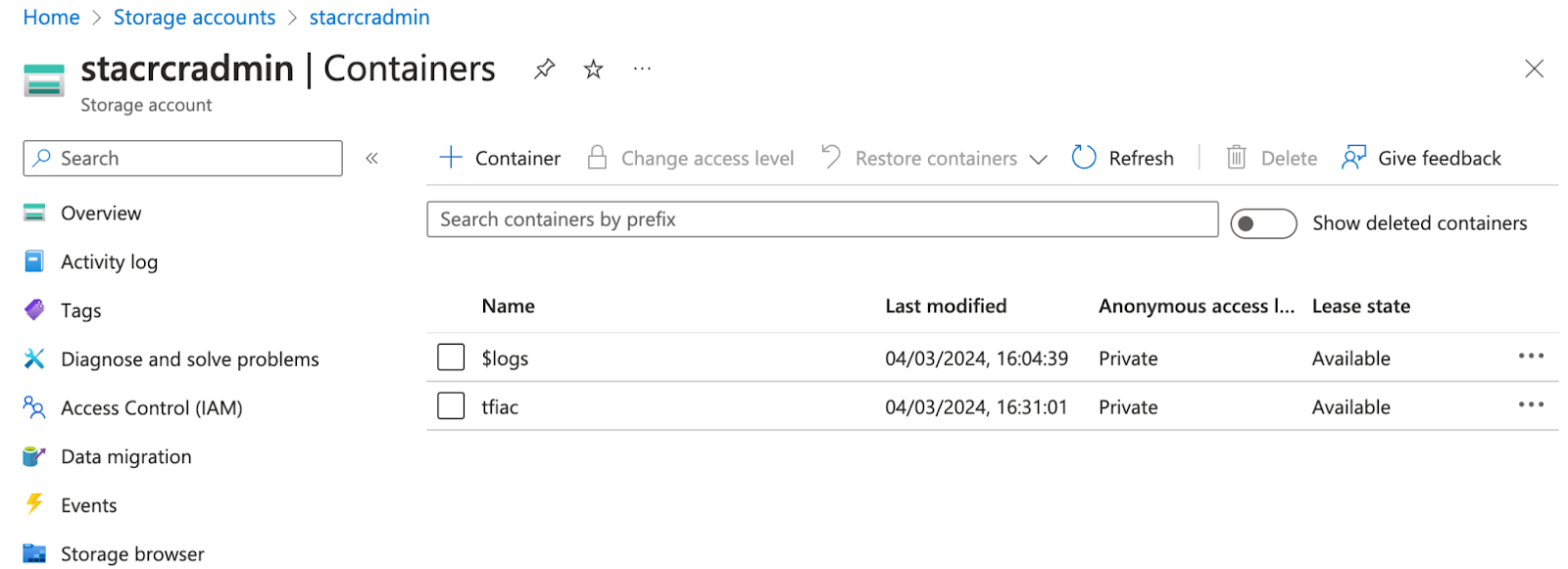
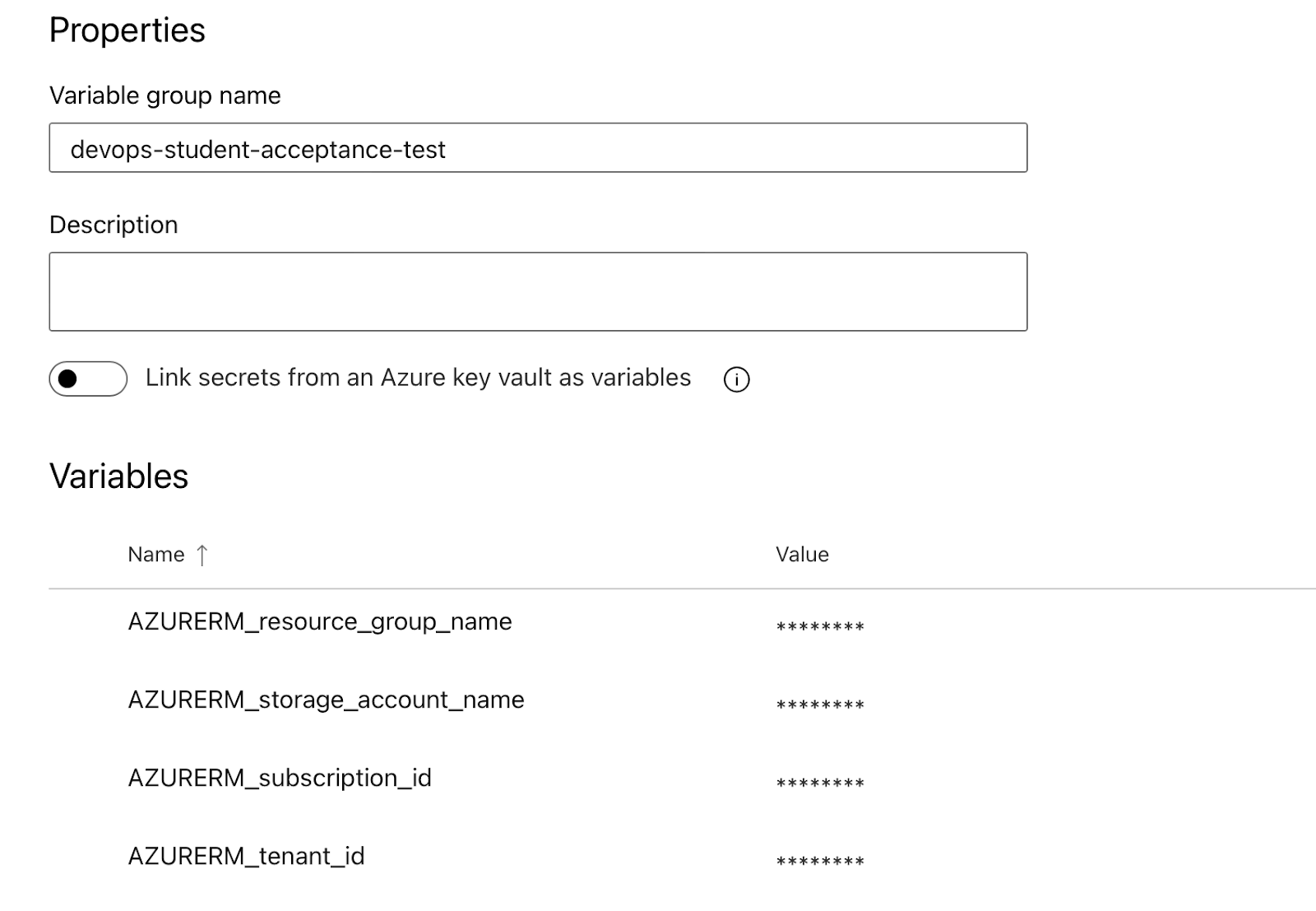
6) Set the Variables in Library Contexts
They need to match your line 42 in iac-student.yml

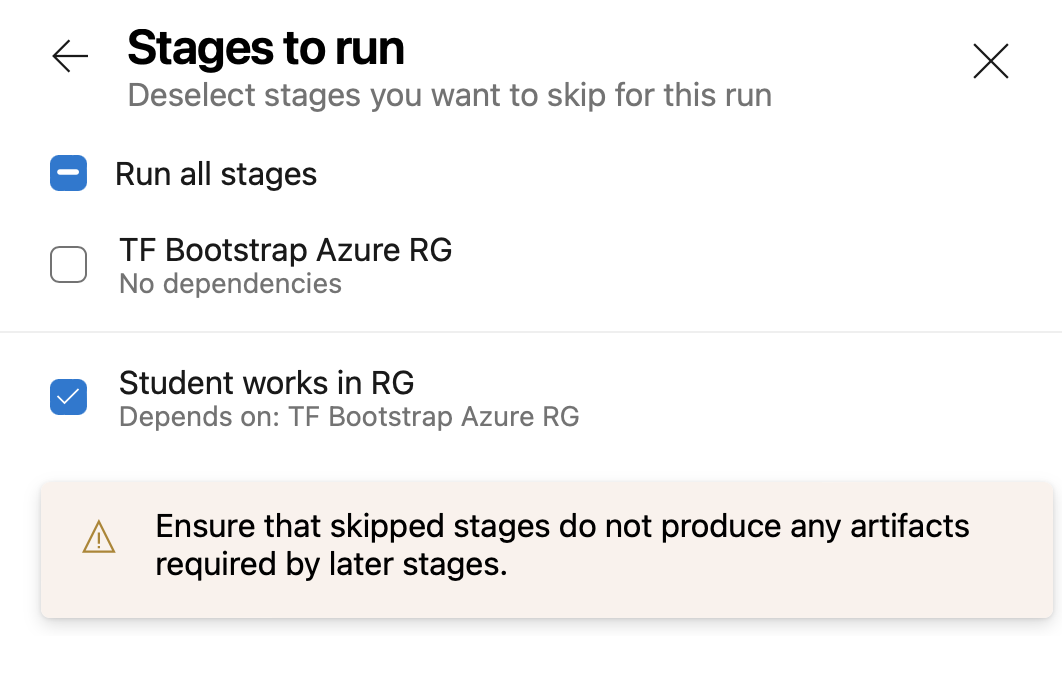
7) Run Terraform in the right stage from the right branch
8) Be aware of your pipeline output
and do not set Enable System Diagnostics -> it will leak all your secrets and you will have to rotate all of them.
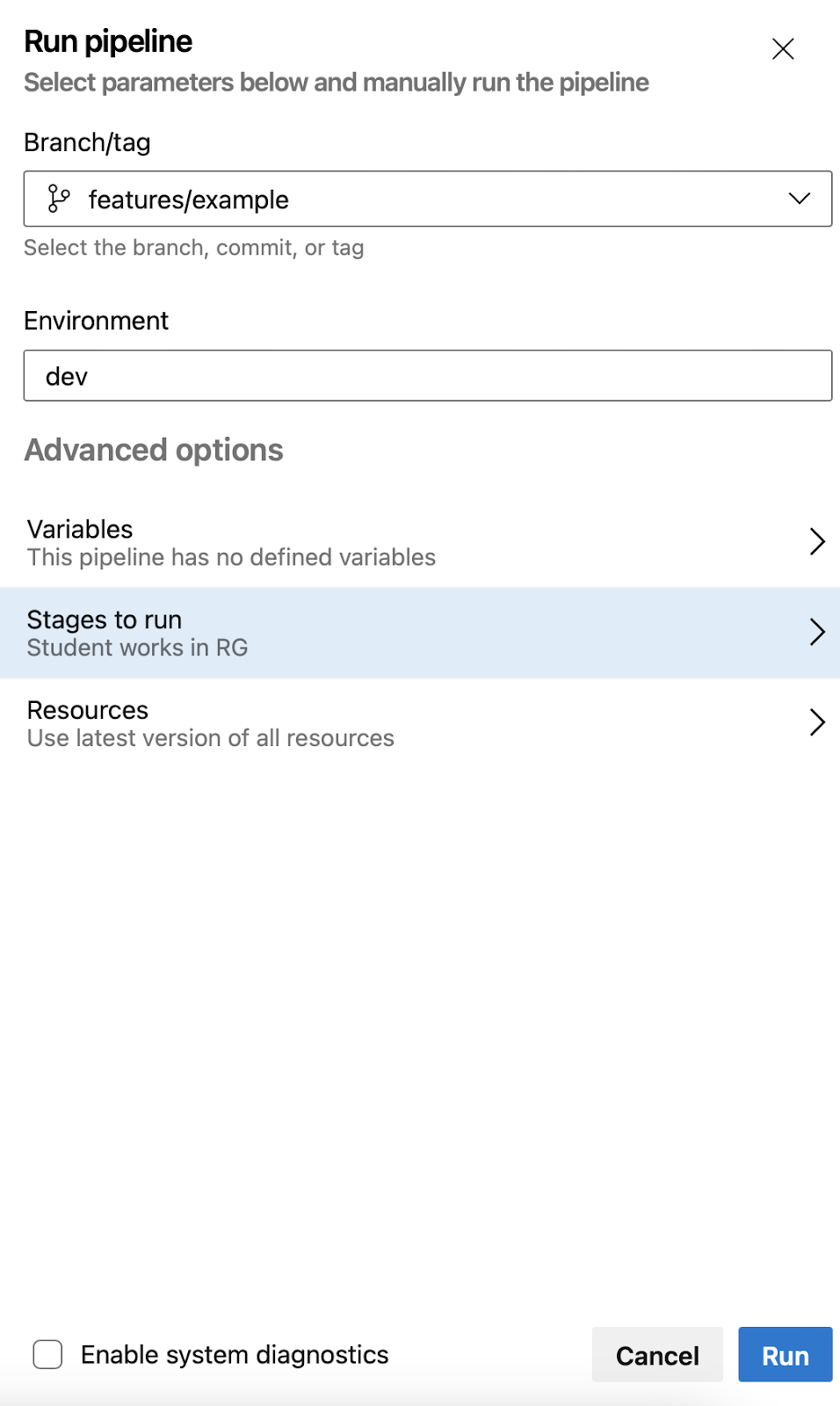
9) Approval Nightmare
well, its a balance, or: you need to find one. That, or meditation
The settings are (all over the place), but for example here: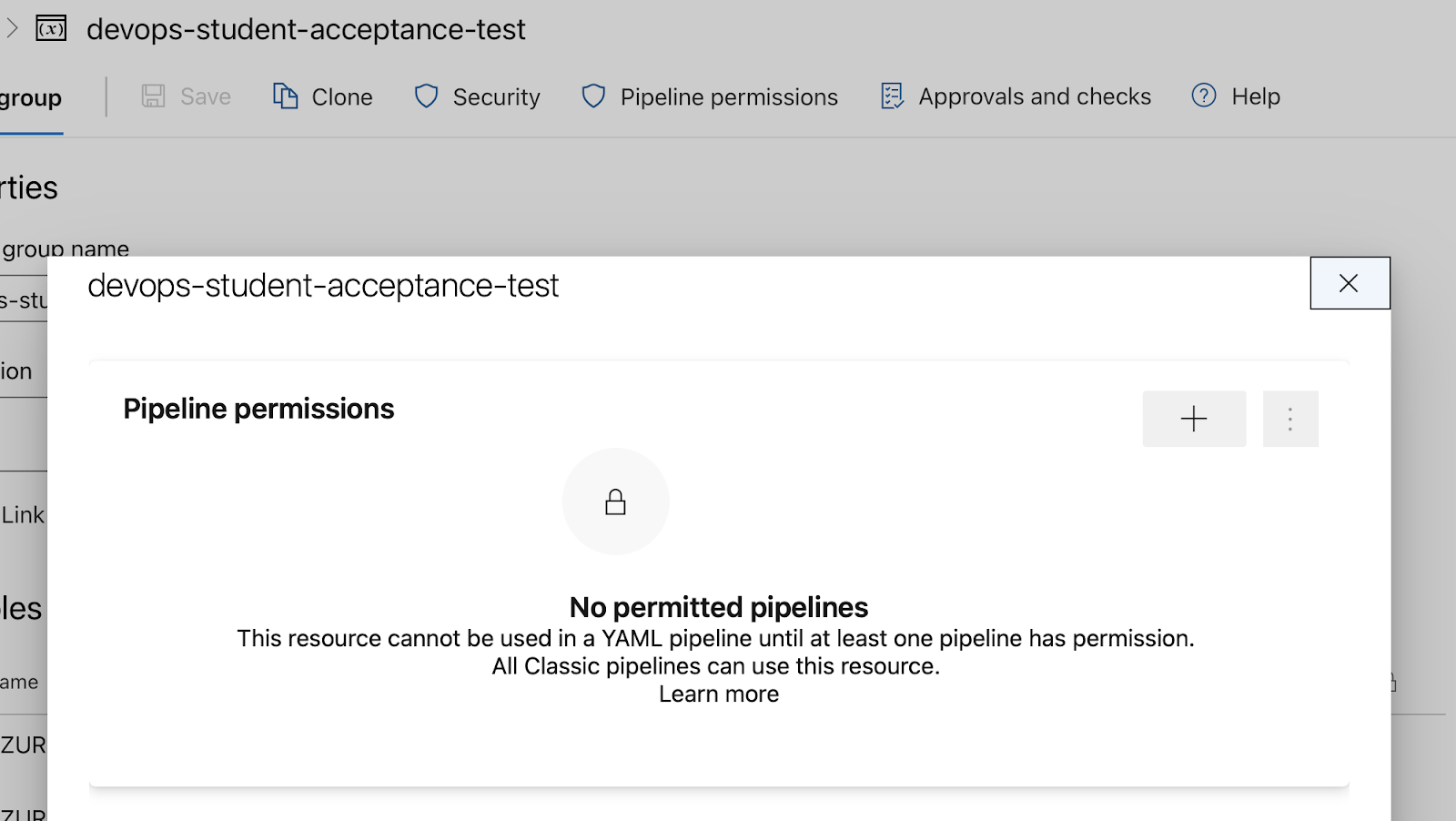
10) Once it works: Be intentional about your terraforming
Just because the terraform syntax is rather copy/paste from hashicorps docs https://registry.terraform.io , doesn't mean terraform is easy:
you need to understand the infrastructure that underlies the syntax. If, for example, you are dealing with DNS, you need to be aware that DNS is typically a very sensitive thing, even though changing records via terraform is extremely easy.
Summary
Once it's setup, it's a joy. But in its seeming simplicity lies a lot of danger, and even though you were likely annoyed by the amount of approval pop-ups -> they can save your production system.
Always test IaC workflows by creating entirely identical systems on branches, before accepting a PR.
IaC testing is time-consuming and often requires multiple cloud accounts (some of which you might want to occasionally completely delete).
Gotchas
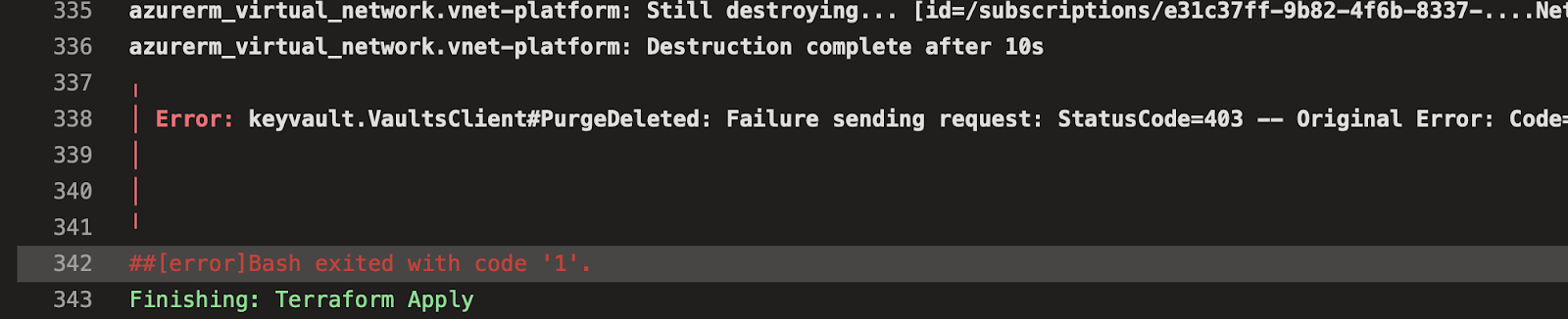
Here is a classical Terraform situation, where you have a resource that cannot directly be destroyed
and the typical solution is : to run terraform destroy twice 😛
You survived the setup: Awesome, take a moment to be grateful
Now, we can use the power of terraforming to create pretty much anything. We will be using Azure for this exercise, as the network (compared to GCP) and the IAM (compared to AWS) is most straightforward. Most other clouds are similar enough, but network and IAM are always the most proprietary. Later, in May, we will compare the network setup with that on Openstack and on GCP, for an equivalent cluster deployment and in June, we will work with hybrid cloud deployments. The following exercise is not a best practice architecture, in fact, the network and the ssh access via traditional firewall is decidedly NOT a good idea.
In the homework, you ll work towards a more best-practice design ( buzzword "ZeroTrust")
Behind the scenes: where is our build agent?
We will now setup step by step a simple VM and then we will setup a destroy pipeline for the simple VM.
Optional exercises
TF loops:
Write a loop using count and one using for_each , report (or write down) the difference.
Note: Please use a very small array to loop over
Ansible:
To compare with Ansible, l run a simple script on the VM to create a cron job that updates it and shuts it off, you would have to add a pipeline step that runs ansible. In iac-student.yaml, only on your branch

(Taken from Terraform up and running, 3rd edition)
We will discuss billing before your homework , make sure you check out that you can see your budget in the Azure subscription (maybe bookmark it)
Remember the discussion on billing https://learn.microsoft.com/en-us/azure/cost-management-billing/costs/tutorial-acm-create-budgets
In this homework, you will NOT be using any SKUs other than the ones specified, no public IPs, create no new resource groups and do not use any licensed products from the marketplace.
In your homework, you will design a private network , a subnetwork and a network security group that has a "default deny".
In this subnet lives a linux host of the smallest SKU you can find and priority = spot . You must configure it such that you can connect from your laptop to it via tailscale. (you can use https://www.merrell.dev/using-tailscale-with-an-azure-linux-vm-and-terraform/ as inspiration)
Your linux vm must be sleeping by default, please monitor your budget consumption and report the cost and how to use it in your branch in a Readme.md
You are expected to have all this by Tuesday March 12 2024, such that you can do the next class on it.
Congratulations, you've successfully setup Terraform and deployed your first VM using 100% automation!