Welcome to DataSecurity, this lab is a basic demonstration of a bad hashing algorithm versus a best practice algorithm
Last Updated: 2024-01-08
Why
Hashes are used to help identify integrity of a system. This lab demonstrates what a hash algorithm should not behave like
What
We will cover the following topics:
- A Hash collision
How should I prepare
- No preparation is required
What you'll need
- A browser (this lab was only tested on Chrome)
- A laptop with internet
Desired Learning Outcome
- Understand Hash functions general concepts
What you'll learn
- Understand how all hash functions work and why that helps identify integrity
Homework or Preparation
Prepare
- Remind yourself of the CIA triad
The basic concept of a Hash function
Hashing is the process of converting input of any size into a fixed-size string of text, using a mathematical function known as a hash function. The output, known as a hash value or hash code, typically looks like a random string of characters.
Properties of Hash Functions:
- Deterministic: For a given input, the output (hash) will always be the same.
- Fixed Size: Regardless of the size of the input data, the output hash length stays the same.
- Efficiency: Hash functions compute quickly.
- Preimage Resistance: It's computationally infeasible to generate the original input value given only the hash output.
- Collision Resistance: It's extremely difficult (but not impossible) to find two different inputs that hash to the same output.
Collisions in Hashing:
While hash functions are designed to minimize collisions (situations where different inputs produce the same output), they're not entirely avoidable due to the fixed size of the hash output. Good hash functions make these collisions extremely rare.
- Hashing vs Encryption:
Hashing and encryption are different. Encryption is a two-way function; data that is encrypted can be decrypted with the correct key. Hashing, however, is a one-way function that scrambles plain text to produce a unique message digest. With a properly designed algorithm, there is no way to reverse the hashing process to reveal the original password.
Seeing is believing
Three files that are the same (or are they?)
Please open this in a separate window (in Chrome) https://austriandatalab.github.io/webvm/
First some basics
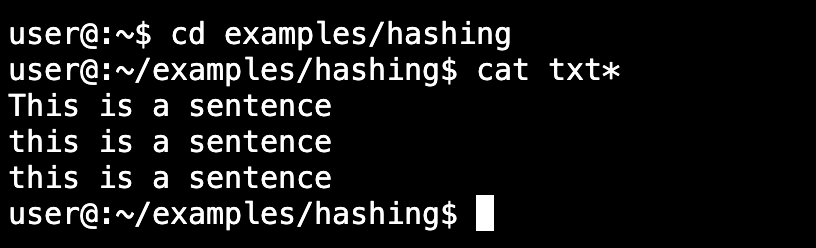
user@:~$ cd examples/hashing user@:~/examples/hashing$ cat txt*
You should now see that there are 3 very similar entries in those 3 text files:
Now, lets check with the first hash function md5 and now it's your job to explain why txt2 and txt3 differ:
user@:~/examples/hashing$ md5 txt* f51996e00c0d41e8958e01982bb2232b txt1 d48ff54287ef1a430b076c2d942e5040 txt2 a8c81c60e0c485be93c4d1e991263695 txt3
Two pdfs that are the same (or are they?)
In the same folder, you find two pdfs, let's have a quick look:
user@:~/examples/hashing$ ls -lah | grep pdf -rw-r--r-- 1 root root 413K Jan 8 13:10 shattered-1.pdf -rw-r--r-- 1 root root 413K Jan 8 13:10 shattered-2.pdf
Ok, now lets create the hash of those two, as well . This time we use
user@:~/examples/hashing$ shasum shattered* 38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-1.pdf 38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-2.pdf
This means, they are the same, right?
Exercise: the two files are on our github https://github.com/AustrianDataLAB/webvm/blob/features/hashinglab/examples/hashing/shattered-1.pdf and https://github.com/AustrianDataLAB/webvm/blob/features/hashinglab/examples/hashing/shattered-2.pdf
You don't have to download them, but you can in-browser view them. Would you say they are the same?
Solution: Using an up-to-date hash algorithm sha256
user@:~/examples/hashing$ shasum -a 256 shattered* 2bb787a73e37352f92383abe7e2902936d1059ad9f1ba6daaa9c1e58ee6970d0 shattered-1.pdf d4488775d29bdef7993367d541064dbdda50d383f89f0aa13a6ff2e0894ba5ff shattered-2.pdf
And here we go: they are not the same, so our eyes work just fine.
What you'll need
- A browser (this lab was only tested on Chrome)
- A laptop with internet
Desired Learning Outcome
- Be confident with a relational database
- Understand what is unique about RMDBs
- See the difference between a well designed model and a haphazard one
Homework or Preparation
Prepare
- none
PreRead
- none
SQL Lite : meet the playground
SQLite is a software library that provides a relational database management system (RDBMS). It is light-weight in terms of setup, database administration, and required resources.
Here are some key characteristics of SQLite:
- Serverless: SQLite doesn't require a separate server process or system to operate. The SQLite database is integrated with the application that accesses the database.
- Zero-Configuration: No setup or administration required. A complete SQLite database is stored in a single cross-platform disk file.
- Compact: A minimal SQLite setup can be as small as 600 KiB, depending on the target platform and compiler optimization settings.
- Transactional: SQLite transactions are fully ACID-compliant, allowing safe access from multiple processes or threads.
- Self-Contained: A single library contains the entire database system, which integrates directly into a host application.
- Cross-Platform: The SQLite file format is identical on all platforms.
SQLite is often used as a local database for small to medium-sized applications, as well as for development and testing. For larger applications where multiple users or high volumes of data are expected, a larger database system like MySQL, PostgreSQL, or SQL Server might be more appropriate.
Play around, you can't destroy anything
Please open this in a separate window (in Chrome) https://austriandatalab.github.io/webvm/
Don't press refresh unless you want to completely wipe all progress.
- Open the database:
Get started in the webVM
user@:~$ cd examples/db user@:~/examples/db$ sqlite3 chinook.db
- List all tables:
.tables
- Show the schema of a table (for example, the albums table):
.schema albums
Here we can observe the following
- [AlbumId] INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL: This creates a column named AlbumId that is of type INTEGER. This column is the primary key for the table, meaning it uniquely identifies each record in the table. AUTOINCREMENT means that each new record will automatically be assigned an AlbumId that is one greater than the AlbumId of the previous record. NOT NULL means that this column must always have a value.
- [Title] NVARCHAR(160) NOT NULL: This creates a column named Title that is of type NVARCHAR(160), meaning it can hold a string of up to 160 characters. NOT NULL means that this column must always have a value.
- [ArtistId] INTEGER NOT NULL: This creates a column named ArtistId that is of type INTEGER. NOT NULL means that this column must always have a value.
- FOREIGN KEY ([ArtistId]) REFERENCES "artists" ([ArtistId]) ON DELETE NO ACTION ON UPDATE NO ACTION: This line sets up a foreign key constraint. It means that the ArtistId in the albums table references the ArtistId in the artists table. The ON DELETE NO ACTION and ON UPDATE NO ACTION clauses mean that if the referenced record in the artists table is deleted or updated, no action will be taken. This could result in a foreign key violation if you try to delete or update a record in the artists table that is referenced by a record in the albums table.
- CREATE INDEX [IFK_AlbumArtistId] ON "albums" ([ArtistId]): This statement creates an index on the ArtistId column of the albums table. An index can speed up queries that filter or sort by the ArtistId. The index is named IFK_AlbumArtistId.
- Select data from a table (for example, the first 10 rows from the albums table):
SELECT * FROM albums LIMIT 10;
- Join two tables together (for example, join albums and artists to show album titles with their corresponding artist names):
SELECT albums.Title, artists.Name FROM albums INNER JOIN artists ON albums.ArtistId = artists.ArtistId LIMIT 10;
- Insert a new row into a table (for example, insert a new artist into the artists table):
INSERT INTO artists (Name) VALUES ('New Artist');
- Update a row in a table (for example, change the name of the artist you just added):
UPDATE artists SET Name = 'Updated Artist' WHERE Name = 'New Artist';
- Delete a row from a table (for example, delete the artist you just added):
DELETE FROM artists WHERE Name = 'Updated Artist';
- Exit SQLite:
.quit
Good Data Model:
The chinook database is a good example of a normalized data model. It has separate tables for artists, albums, tracks, genres, media types, playlists, customers, invoices, and employees. Each table has a primary key, and there are foreign keys to link related records across tables.
For example, to get the details of a track, you might use a query like this:
SELECT
tracks.Name AS Track, albums.Title AS Album, artists.Name AS Artist, genres.Name AS Genre
FROM
tracks
INNER JOIN albums ON tracks.AlbumId = albums.AlbumId
INNER JOIN artists ON albums.ArtistId = artists.ArtistId
INNER JOIN genres ON tracks.GenreId = genres.GenreId
WHERE
tracks.TrackId = 1;
This query performs well because it's able to use the relational structure of the database to efficiently gather data from multiple tables.
Bad Data Model:
A bad data model might involve denormalization that leads to data redundancy and update anomalies. For example, imagine if the chinook database had a single table where each row contained all the details of a track, including the album title, artist name, and genre name. This would mean that the same album title, artist name, and genre name would be repeated in many rows.
Lets create the table first:
CREATE TABLE denormalized_tracks (
TrackId INTEGER PRIMARY KEY,
TrackName TEXT NOT NULL,
AlbumTitle TEXT,
ArtistName TEXT,
GenreName TEXT
);
Now, insert data into it
INSERT INTO denormalized_tracks (TrackId, TrackName, AlbumTitle, ArtistName, GenreName)
SELECT
tracks.TrackId, tracks.Name, albums.Title, artists.Name, genres.Name
FROM
tracks
INNER JOIN albums ON tracks.AlbumId = albums.AlbumId
INNER JOIN artists ON albums.ArtistId = artists.ArtistId
INNER JOIN genres ON tracks.GenreId = genres.GenreId;
Now, we have a table that give us a lot of flexibility (seemingly)
SELECT
TrackName, AlbumTitle, ArtistName, GenreName
FROM
denormalized_tracks
WHERE
TrackId = 1;
While this query might seem simpler, the underlying data model is inefficient. The redundancy in the data increases the size of the database and the risk of inconsistencies. Also, updates to the data (like changing the name of an artist) would require changes in many places, which can be slow and error-prone.
Think about, e.g. how would you update a typo in the GenreName for the denomalized model? (select * from denormalized_tracks limit 10)
Can you draw on paper how the update statement would be different for a denormalized vs a normalized model?
Comment: There are databases specialized in the exact opposite (e.g. column databases such as SAP Hana would prefer the denomalized model for a results table, because its engine is designed for it).
Here are some examples to inspire you, feel free to change them
- Patients Table: Stores information about each patient.
CREATE TABLE Patients (
PatientId INTEGER PRIMARY KEY,
FirstName TEXT NOT NULL,
LastName TEXT NOT NULL,
DateOfBirth TEXT,
Gender TEXT
);
- Treatments Table: Stores information about each treatment.
CREATE TABLE Treatments (
TreatmentId INTEGER PRIMARY KEY,
TreatmentName TEXT NOT NULL,
Description TEXT
);
- Researchers Table: Stores information about each researcher.
CREATE TABLE Researchers (
ResearcherId INTEGER PRIMARY KEY,
FirstName TEXT NOT NULL,
LastName TEXT NOT NULL,
Department TEXT
);
- Studies Table: Stores information about each study, including the patient, the treatment, the researcher who conducted the study, and the result.
CREATE TABLE Studies (
StudyId INTEGER PRIMARY KEY,
PatientId INTEGER,
TreatmentId INTEGER,
ResearcherId INTEGER,
Result TEXT,
Date TEXT,
FOREIGN KEY (PatientId) REFERENCES Patients (PatientId),
FOREIGN KEY (TreatmentId) REFERENCES Treatments (TreatmentId),
FOREIGN KEY (ResearcherId) REFERENCES Researchers (ResearcherId)
);
How do you deal with confidential data contained in these tables?
SQLite doesn't have built-in data masking features like some other database systems. However, you can achieve a similar effect by creating views that exclude the sensitive columns.
For example, if the Patients table has a sensitive column DateOfBirth, you can create a view that includes all columns except this one:
CREATE VIEW Patients_Public AS
SELECT PatientId, FirstName, LastName, Gender
FROM Patients;
Now, you can query Patients_Public instead of Patients to get patient information without revealing any dates of birth:
SELECT * FROM Patients_Public;
Remember, views do not provide security against unauthorized access. They are just a convenience for queries. To protect sensitive data, you should implement proper access controls at the database or application level.
For more advanced data masking, you would typically use a more feature-rich database system, or handle the masking at the application level. For example, you could replace sensitive data with placeholders or hashed values before inserting it into the database.
Anonymizing
Discuss if the following is a good idea:
CREATE TABLE AnonymizedPatients AS
SELECT
PatientId,
'Patient ' || PatientId AS FirstName,
NULL AS LastName,
NULL AS DateOfBirth,
Gender
FROM
Patients;
Please see
https://www.enisa.europa.eu/publications/data-protection-engineering
https://www.enisa.europa.eu/publications/deploying-pseudonymisation-techniques
Congratulations, you've successfully completed this training on hashing collisions and some datamodelling.
What's next?
- For immudb https://play.codenotary.com/
Further reading
- If you d like to learn how to use a DocumentDB , check out e.g. https://learn.mongodb.com/learning-paths/data-modeling-for-mongodb